Breast Cancer Diagnostic And Drug Technologies Market Trends, Forecast & Industry Outlook 2035
Health |
2026-07-13 10:38:18
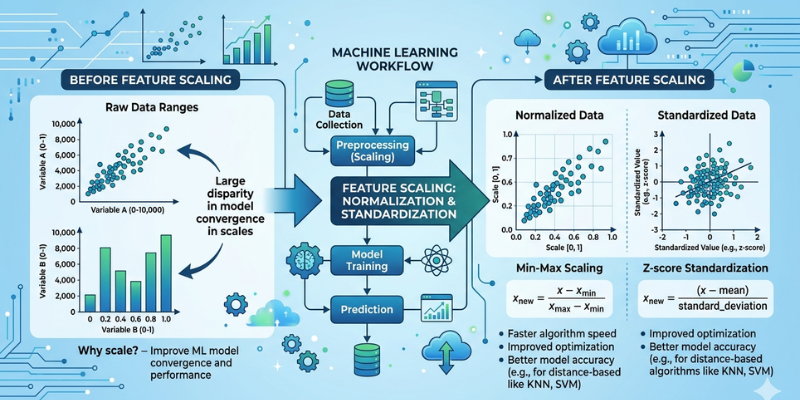
Feature scaling and normalization are important steps in data preprocessing. They help prepare data for machine learning algorithms by ensuring that numerical values are on a similar scale. When features have very different ranges, some algorithms may give more importance to larger values and ignore smaller ones. This can influence the precision and functionality of a model.
As machine learning projects become more complex, understanding these techniques becomes essential for aspiring data professionals. If you want to build a strong foundation in data preprocessing and machine learning concepts, consider exploring Data Science Courses in Bangalore at FITA Academy to strengthen your practical knowledge.
Feature scaling involves adjusting the range of numerical features in a dataset. Different variables often have different units and value ranges. For example, age may range from 18 to 60, while annual income may range from thousands to millions. Such differences can influence the behavior of machine learning algorithms.
By scaling features, all variables contribute more fairly to the learning process. This helps algorithms analyze patterns without being biased toward features with larger values. Feature scaling is commonly used in algorithms that rely on distance calculations, such as K-Nearest Neighbors and clustering methods.
Many machine learning algorithms perform mathematical calculations based on distances or gradients. When one feature has much larger values than another, it can dominate these calculations. As a result, the model may not learn effectively from all available information.
Feature scaling improves training efficiency and often leads to better model performance. It can also help optimization algorithms reach solutions faster. This makes the training process more stable and reliable.
Another benefit of feature scaling is improved consistency across datasets. When data is scaled properly, it becomes easier to compare features and interpret model behavior. This is particularly beneficial when dealing with numerous variables in practical projects.
Normalization is a specific type of feature scaling. It transforms values into a fixed range, often between 0 and 1. This process helps ensure that all features share a common scale regardless of their original ranges.
Normalization is particularly useful when data does not follow a normal distribution and when algorithms depend heavily on distance measurements. It helps prevent large-value features from overpowering smaller-value features during training.
For learners who want hands-on experience with data preprocessing techniques and machine learning workflows, taking a Data Science Course in Hyderabad can offer significant hands-on experience with these ideas.
Although the terms are often used together, feature scaling and normalization are not exactly the same. Feature scaling is a broader concept that includes several methods for adjusting data ranges. Normalization is one specific method within that category.
The choice between different scaling techniques depends on the dataset and the algorithm being used. Some algorithms benefit from normalization, while others may perform better with alternative scaling methods. Understanding the characteristics of your data is important before selecting an approach.
It is also important to remember that scaling does not improve the quality of data itself. Instead, it helps algorithms process the data more effectively by reducing the impact of differing feature magnitudes.
Feature scaling is commonly applied in various machine learning tasks, including customer segmentation, recommendation systems, fraud detection, and predictive analytics. In these scenarios, datasets often contain variables with different units and ranges.
Without scaling, models may produce less accurate results or require more time to train. Applying the right preprocessing techniques can significantly improve overall model performance and help create more reliable predictions.
Feature scaling and normalization are fundamental concepts in data science and machine learning. They help ensure that features contribute fairly during model training and reduce the risk of biased learning. By transforming data into comparable ranges, these techniques improve model efficiency, stability, and accuracy.
Having a solid grasp of preprocessing techniques can greatly impact the effectiveness of a machine learning initiative. If you are looking to deepen your skills and apply these concepts in real-world scenarios, you can join a Data Science Course in Ahmedabad and gain practical experience through structured learning programs.
